The first thing that someone would need when operating or playing around with OKD (better known as OpenShift) is a git version control service. Personally I’m a fan of Gitea and that’s why I’d like to show a way how to run Gitea in a OpenShift environment. Gitea upstream already provides a great container image which I’m are going to use. But as some of you may have already experienced, running an image on docker and running it in OpenShift is two different pairs of shoes. The fact that the Gitea image runs an integrated SSH server means that it doesn’t simply match the widely discussed Web application pattern. Therefore I’m trying to explain some of the difficulties that one might encounter when moving such an application to OpenShift.
My environment consists of a multi-node OpenShift cluster. Obviously Gitea should be high available so that if a node goes down, one would still be able to access the git repositories. One pod is no pod, so Gitea must be deployed with a replica count of at least two. Accessing the pods over HTTP is already solved by the OpenShift default infrastructure via redundant HAProxy routers. I’d probably explain how to achieve a redundant router setup in one of my next blog posts but this time I’d like to emphasis on the Gitea SSH access via NodePort service feature. The following graphic shows a communication overview of such a setup:
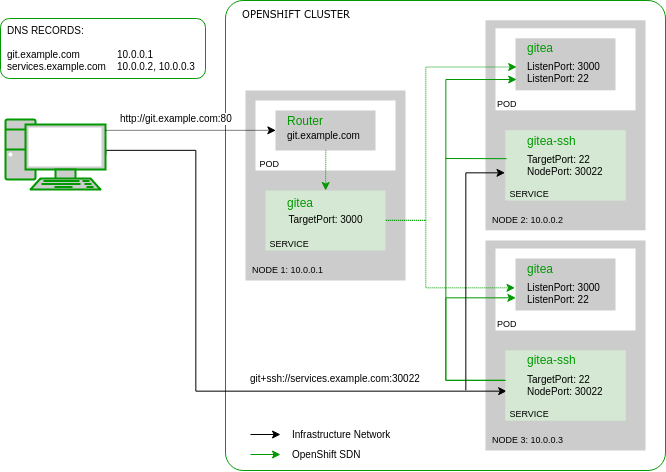
NodePort Service
In OpenShift the Kubernetes Service resource is responsible for directing the traffic (TCP, UDP or SCTP) to the individual application pods. It maps the service name (e.g. ‘gitea’) via SkyDNS to a so-called ClusterIP. This is a virtual IP address that is not assigned to any host or container network interface but still used as packet destination within the cluster SDN (software defined network). After receiving a packet to this so-called ClusterIP the Linux kernel of an OpenShift node rewrites the packet destination to an IP address of an actual application pod and acts as a virtual network load-balancer.
In our example there is a ‘gitea’ service managing the HTTP traffic to port 3000 of the Gitea pod and a ‘gitea-ssh’ service managing the SSH traffic to port 22 of the Gitea pod. Because we can’t use the OpenShift Router as ingress for SSH, the ‘gitea-ssh’ service defines a special type called NodePort. This means that a packet sent to this port (e.g. 30022) on any OpenShift node will be received by the corresponding service and therefore forwarded to a Gitea pod. This is the simplest way how to direct non-HTTP traffic from outside of OpenShift to an application pod and can also be used for e.g. database protocols or Java RMI. Here the corresponding resource definition for the Gitea SSH service:
apiVersion: v1
kind: Service
metadata:
name: gitea-ssh
spec:
ports:
- name: ssh
nodePort: 30022
port: 22
protocol: TCP
targetPort: 22
selector:
app: gitea
deploymentconfig: gitea
sessionAffinity: ClientIP
type: NodePort
The sessionAffinity: ClientIP setting defines “sticky sessions” to avoid distributing multiple requests of the same client to different pods. I didn’t test yet, how SSH would behave without it, but I think it generally makes sense. In a running setup the service additionally shows the discussed ClusterIP which is statically assigned and the endpoints (pod IPs) which may change when pods are started and stopped:
$ oc describe service gitea-ssh
Name: gitea-ssh
Namespace: vcs
Labels: app=gitea
template=gitea-persistent-template
Annotations:
Selector: app=gitea,deploymentconfig=gitea
Type: NodePort
IP: 172.30.8.9
Port: ssh 22/TCP
TargetPort: 22/TCP
NodePort: ssh 30022/TCP
Endpoints: 10.129.2.44:22,10.130.3.71:22
Session Affinity: ClientIP
External Traffic Policy: Cluster
Events:
From within the cluster, the Gitea SSH service can be reached via service name (extended with OpenShift project name, here ‘vcs’) DNS entry or directly via ClusterIP:
$ host gitea-ssh.vcs.svc gitea-ssh.vcs.svc has address 172.30.8.9 $ ssh git@gitea-ssh.vcs.svc PTY allocation request failed on channel 0 Hi there, You've successfully authenticated, but Gitea does not provide shell access. If this is unexpected, please log in with password and setup Gitea under another user. Connection to gitea-ssh.vcs.svc closed.
From outside the cluster, the Gitea SSH service can be reached via NodePort on any OpenShift node. To avoid a dependency on a single node in the git repository URL you can define multiple DNS entries using the same name (e.g. services.example.com) to all OpenShift node addresses:
$ host services.example.com services.example.com has address 10.0.0.2 services.example.com has address 10.0.0.3 $ ssh -p 30022 git@services.example.com PTY allocation request failed on channel 0 Hi there, You've successfully authenticated, but Gitea does not provide shell access. If this is unexpected, please log in with password and setup Gitea under another user. Connection to services.example.com closed.
Issues with NodePort
Port Assignment
The NodePort mechanism is allocating the corresponding port on each OpenShift node. To avoid a clash with node services such as the DNS resolver or the OpenShift node service the port range is restricted. It can be configured in the /etc/origin/master/master-config.yml with the option servicesNodePortRange and defaults to 30000-32767. Obviously multiple applications in the same cluster cannot use the same port and traffic to the chosen port must be allowed by the host firewall on the OpenShift nodes.
Node Groups
NodePorts are always allocated on every OpenShift cluster host running the node service which also includes the OpenShift master servers. OpenShift doesn’t provide a way to restrict the involved hosts to a subset. In my example I choose to restrict the hosts receiving traffic by only adding a limited number of nodes to the service DNS entry and block access on the others via iptables. If you don’t use an application load-balancer in front of the OpenShift routers you could also re-use the wildcard DNS entry defined for the HTTP traffic. The NodePort traffic would then follow the same path as the normal Web traffic.
Node Failure
If one OpenShift node goes down a client trying to access the Gitea SSH service might still try to connect to the unreachable host. Fortunately, the default SSH implementation used by the git command line client is quite tolerant and simply retries with another IP address. When testing this case I therefore haven’t experienced a major issue except a slight connection delay. The failure behavior might be different for other git clients or other application protocols altogether and is definitely not ideal but simple instead.
One way to improve this failure scenario would be to add a real TCP load-balancer in front of the NodePort but then there would be another piece of infrastructure that must be managed synchronously with the OpenShift infrastructure and which might be a new single point of failure.
Container with root Permissions
When starting the upstream Gitea container image in OpenShift you might likely encounter a startup failure with the following error message in the log:
s6-svscan: fatal: unable to mkfifo .s6-svscan/control: Permission denied
The Gitea image, and many other docker images not optimized for the pod concept introduced by Kubernetes, doesn’t start a single application process but a supervisor process (in this case s6) which then spawns multiple different application processes defined in /etc/s6. To do so it wants to create a FIFO in the /etc/s6/.s6-svscan directory which is only writable by the root user which fails as by default processes are started with a random unprivileged account.
Security Context Constraints
Unlike docker, OpenShift controls the actions a pod can do and access with a tight set of rules called Security Context Constraints (SCC). By default the ‘default’ ServiceAccount used to run the application pods is a member of the ‘restricted’ SCC which among other things defines the previously mentioned randomized UID. As Gitea won’t work like this, a less restrictive SCC must be used. After reading the documentation we find, that there is already a predefined SCC which grants us just enough permissions to start our container process as root user without weakening too many other restrictions. The SCC we are heading for is ‘anyuid’. Below I’ll present different approaches how this SCC can now be assigned to the Gitea deployment:
- The OpenShift cluster administrator can add the ‘default’
ServiceAccountof a project to the list of users in the SCC definition. This doesn’t need any special configuration in theDeploymentConfigof the application but also grants every deployment in the corresponding project ‘anyuid’ privileges. In our setup this would be done with the following command, when assuming Gitea should be deployed in the ‘vcs’ project:$ oc adm policy add-scc-to-user anyuid system:serviceaccount:vcs:default
I’m not in favor of this approach as it “hides” the additional permissions in the default
ServiceAccountand prone to break the principle of least privilege by assigning the SCC to potentially more applications than necessary. - Another approach is using a dedicated
ServiceAccountfor the Gitea deployment and only adding that to the ‘anyuid’ SCC. The project owner can create aServiceAccountwith:$ oc create serviceaccount gitea
The cluster administrator then has to add it to the SCC as before:
$ oc adm policy add-scc-to-user anyuid system:serviceaccount:vcs:gitea
In the
DeploymentConfigtheServiceAccountmust be referenced with a entry under thespec.template.speckey:$ oc patch dc/gitea --patch '{"spec":{"template":{"spec":{"serviceAccountName": "gitea"}}}}'The dedicated
ServiceAccountused in this approach already hints that there might be special privileges connected to it and is in my opinion easier to audit. The disadvantage however is the more complex configuration. - Instead of adding every user account individually to the SCC a dedicated user group could be created having the SCC assigned to this group. Individual
ServiceAcccountss would then be added to the group and therefore inherit the SCC. This would follow common practice in identity management to assign permissions to users via privilege groups. Additionally a group management role could be created which then would permit dedicated users not having the ‘cluster-admin’ privilege to manage the group membership. - Unfortunately I couldn’t figure out a true self-service model where a responsible project admin could expand the necessary permissions without the possibility to interfere with other projects. In the documentation of OpenShift (<=3.7) I found a hint that it is/was(?) possible to extend the default
ServiceAccounts available after creating a new project by adding the account name (e.g. ‘anyuid-service-account’) to theserviceAccountConfig.managedNameslist in/etc/origin/master/master-config.yml. While this configuration is still present in newermaster-config.yml, the documentation is gone and I also didn’t find a way how to automatically add a user created like this to the ‘anyuid’ SCC. Maybe it’s possible by somehow modifying the project template. If you have done this before or at least have an idea how this could be done, please drop me a line.
At the end, the way how the ‘anyuid’ SCC is assigned to the Gitea application is unimportant as long as the application pod is allowed to start the s6 supervisor process with root permissions.
Gitea Application Template
The way how OpenShift administrators can provide an application setup ready for instantiation by OpenShift project owners is through Templates. Inspired by the My journey through Openshift blog post, I wanted to create my own Gitea template fixing some issues found in the original template and extending it with the opinionated configuration presented above. You can download it from here.
The template is able to automatically setup Gitea with exception of the ‘anyuid’ SCC configuration. It requires a persistent volume (PV) for storing the git repositories and some static configurations such as the SSH authorized_keys file. By default it will use a SQLite database backend which is also stored in the PV. Optionally you can also give the connection string and credentials of a PostgreSQL or MariaDB backend which can run on OpenShift or externally.
If you want the template to be available in the Service Catalog the YAML file has to be applied to the ‘openshift’ project by a cluster administrator:
$ oc create -f gitea-persistent-template.yaml -n openshift
Afterwards it can be instantiated by any project admin via Service Catalog Web-UI or from the command line via:
$ oc new-project vcs $ oc new-app --template=gitea-persistent -p HTTP_DOMAIN=git.example.com -p SSH_DOMAIN=services.example.com
Alternatively, if no Service Catalog is available, or the template shouldn’t be loaded to OpenShift, the application can also be created directly from the YAML file via:
$ oc new-app -f gitea-persistent-template.yaml -p HTTP_DOMAIN=git.example.com -p SSH_DOMAIN=services.example.com
IMPORTANT: The template will configure Gitea to use a ServiceAccount named according to the parameter APPLICATION_NAME (defaults to ‘gitea’). It must be added to the ‘anyuid’ SCC as described above. E.g.:
$ oc adm policy add-scc-to-user anyuid system:serviceaccount:vcs:gitea
If you have some feedback regarding the template or troubles using it, please open a Github issue. Comments, corrections or general feedback to my article can be posted below. Thanks for reading.