This is the second part of my field report about installing the oVirt 4.4-alpha release on CentOS 8 in a hyperconverged setup. In the first part I was focusing on setting up the GlusterFS storage cluster and now I’m going to describe my experience of the self-hosted engine installation.
If you think about repeating this installation on your hardware please let me remind you: This software is currently in alpha status. This means there are likely still many bugs and rough edges and if you succeed to install it successfully there is no guarantee for updates not breaking everything again. Please don’t try this anywhere close to production systems or data. I won’t be able to assist you in any way if things turn out badly.
Cockpit Hosted-Engine Wizard
Before we can start installing the self-hosted engine, we need to install a few more packages:
# dnf install ovirt-engine-appliance vdsm-gluster
Similar to the GlusterFS setup, also the hosted engine setup can be done from the Cockpit Web interface:
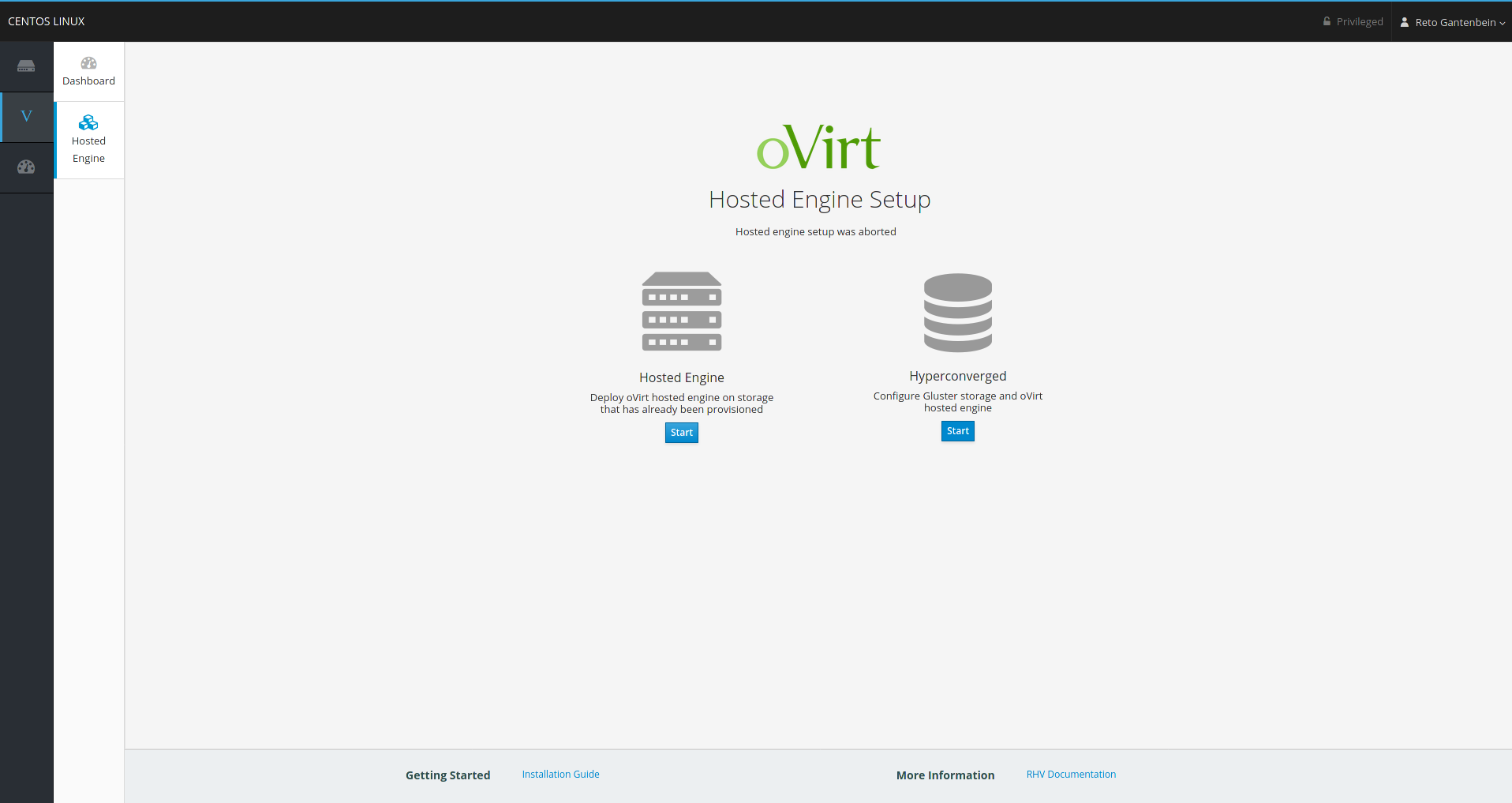
The wizard is also here pretty self-explanatory. There are a few options missing in Web-UI compared to the commandline installer (hosted-engine --deploy) e.g. you cannot customize the name of the libvirt domain which is called ‘HostedEngine’ by default. You must give the common details such as hostname, VM resources, some network settings, credentials for the VM and oVirt and that’s pretty much it:
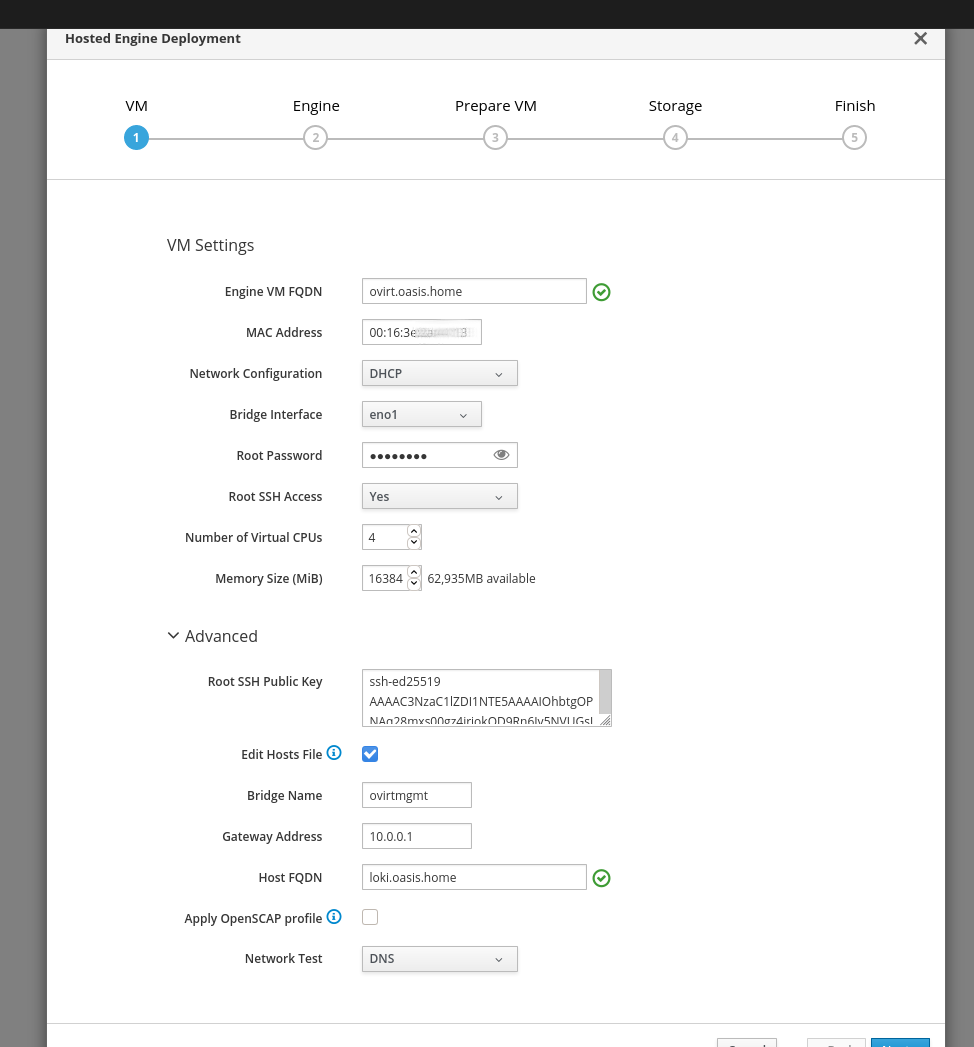
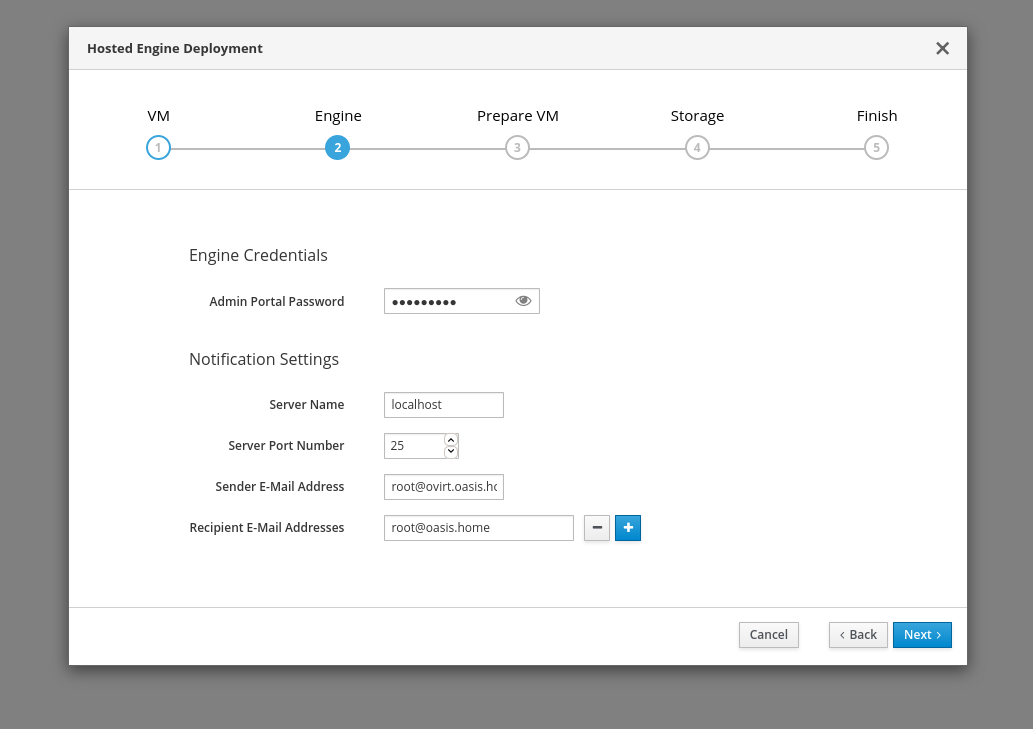
Before you start deploying the VM there is also a quick summary of the settings and then an answer file will be generated. While the GlusterFS setup created a regular Ansible inventory the hosted engine setup has its own INI-format. It’s a useful feature that even when the deployment aborts, it can always be restarted from the Web interface without the need to fill in the form again and again. Indeed, I used this to my advantage a lot because it took me at least 20 attempts before the hosted engine VM was setup successfully.
Troubleshooting hosted-engine issues
Once VM deployment was running I found that the status output in the Cockpit Web interface heavily resembled Ansible output. It seems that a big part of the deployment code in the hosted-engine tool was re-implemented now using the ovirt-ansible-hosted-engine-setup Ansible roles in the background. If you’re familiar with Ansible this definitely simplifies troubleshooting and also allows a better understanding what is going on. Unfortunately there is still a layer of hosted-engine code above Ansible so that I couldn’t figure out, if it’s possible to run a playbook from the shell that would do the same setup.
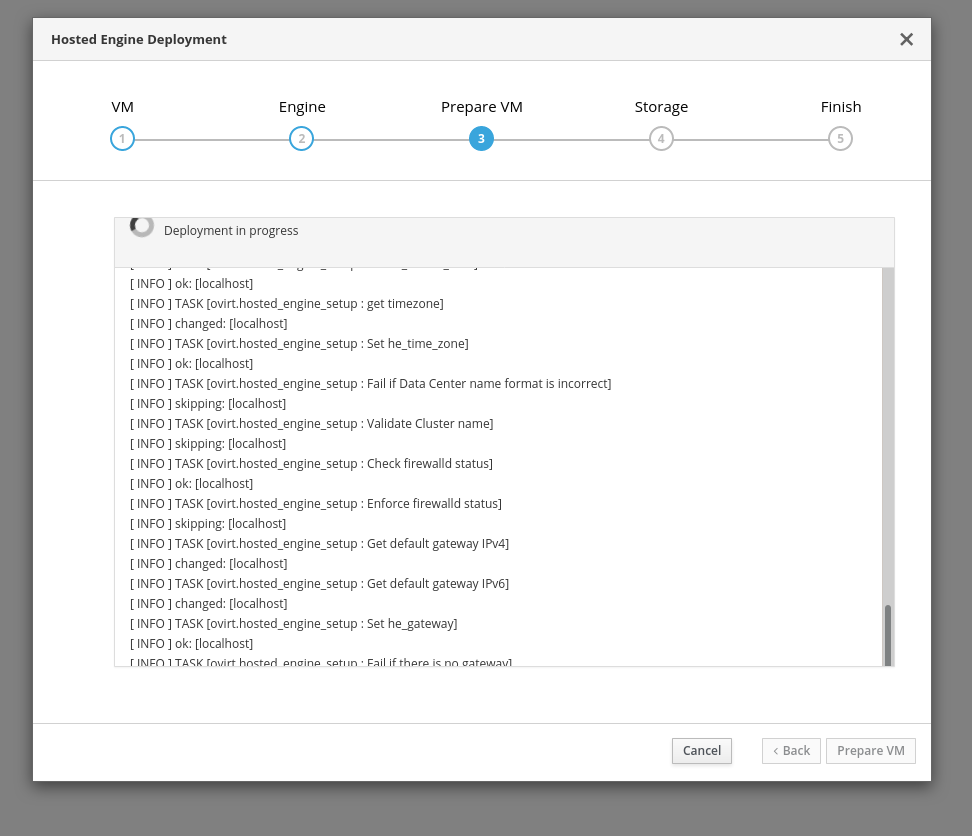
Obviously it didn’t take long for an issue to pop-up:
- The first error was that Ansible couldn’t connect to the hosted-engine VM that was freshly created from the oVirt appliance disk image. The error output in the Web interface is rather limited but also here a log file exists that can be found at a path like
/var/log/ovirt-engine/setup/ovirt-engine-setup-20200218154608-rtt3b7.log. In the log file I found:2020-02-18 15:32:45,938+0100 DEBUG ansible on_any args localhostTASK: ovirt.hosted_engine_setup : Wait for the local VM kwargs 2020-02-18 15:35:52,816+0100 ERROR ansible failed { "ansible_host": "localhost", "ansible_playbook": "/usr/share/ovirt-hosted-engine-setup/ansible/trigger_role.yml", "ansible_result": { "_ansible_delegated_vars": { "ansible_host": "ovirt.oasis.home" }, "_ansible_no_log": false, "changed": false, "elapsed": 185, "msg": "timed out waiting for ping module test success: Using a SSH password instead of a key is not possible because Host Key checking is enabled and sshpass does not support this. Please add this host's fingerprint to your know n_hosts file to manage this host." }, "ansible_task": "Wait for the local VM", "ansible_type": "task", "status": "FAILED", "task_duration": 187 }A manual SSH login with the root account on the VM was possible after accepting the fingerprint. Maybe this is still a bug or I missed a setting somewhere, but the easiest way to solve this was to create a
~root/.ssh/configfile on the hypervisor host with the following content. The hostname is the hosted-engine FQDN:Host ovirt.oasis.home StrictHostKeyChecking accept-newEach installation attempt will make sure that the previous host key is deleted from the
known_hostsfile so no need to worry about changing keys on multiple installation tries. The deployment could simply be restarted by pressing the “Prepare VM” button once again. - During the next run the connection to the hosted-engine VM succeeded and it nearly completed all of the setup task within the VM but then failed when trying to restart the
ovirt-engine-dwhdservice:2020-02-18 15:48:45,963+0100 INFO otopi.plugins.ovirt_engine_setup.ovirt_engine_dwh.core.service service._closeup:52 Starting dwh service 2020-02-18 15:48:45,964+0100 DEBUG otopi.plugins.otopi.services.systemd systemd.state:170 starting service ovirt-engine-dwhd 2020-02-18 15:48:45,965+0100 DEBUG otopi.plugins.otopi.services.systemd plugin.executeRaw:813 execute: ('/usr/bin/systemctl', 'start', 'ovirt-engine-dwhd.service'), executable='None', cwd='None', env=None 2020-02-18 15:48:46,005+0100 DEBUG otopi.plugins.otopi.services.systemd plugin.executeRaw:863 execute-result: ('/usr/bin/systemctl', 'start', 'ovirt-engine-dwhd.service'), rc=1 2020-02-18 15:48:46,006+0100 DEBUG otopi.plugins.otopi.services.systemd plugin.execute:921 execute-output: ('/usr/bin/systemctl', 'start', 'ovirt-engine-dwhd.service') stdout: 2020-02-18 15:48:46,006+0100 DEBUG otopi.plugins.otopi.services.systemd plugin.execute:926 execute-output: ('/usr/bin/systemctl', 'start', 'ovirt-engine-dwhd.service') stderr: Job for ovirt-engine-dwhd.service failed because the control process exited with error code. See "systemctl status ovirt-engine-dwhd.service" and "journalctl -xe" for details. 2020-02-18 15:48:46,007+0100 DEBUG otopi.context context._executeMethod:145 method exception Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/otopi/context.py", line 132, in _executeMethod method['method']() File "/usr/share/ovirt-engine/setup/bin/../plugins/ovirt-engine-setup/ovirt-engine-dwh/core/service.py", line 55, in _closeup state=True, File "/usr/share/otopi/plugins/otopi/services/systemd.py", line 181, in state service=name, RuntimeError: Failed to start service 'ovirt-engine-dwhd' 2020-02-18 15:48:46,008+0100 ERROR otopi.context context._executeMethod:154 Failed to execute stage 'Closing up': Failed to start service 'ovirt-engine-dwhd' 2020-02-18 15:48:46,009+0100 DEBUG otopi.context context.dumpEnvironment:765 ENVIRONMENT DUMP - BEGIN 2020-02-18 15:48:46,010+0100 DEBUG otopi.context context.dumpEnvironment:775 ENV BASE/error=bool:'True' 2020-02-18 15:48:46,010+0100 DEBUG otopi.context context.dumpEnvironment:775 ENV BASE/exceptionInfo=list:'[(, RuntimeError("Failed to start service 'ovirt-engine-dwhd'",), )]' 2020-02-18 15:48:46,012+0100 DEBUG otopi.context context.dumpEnvironment:779 ENVIRONMENT DUMP - END Fortunately I was able to login to the hosted-engine VM and found the following blunt error:
-- Unit ovirt-engine-dwhd.service has begun starting up. Feb 18 15:48:46 ovirt.oasis.home systemd[30553]: Failed at step EXEC spawning /usr/share/ovirt-engine-dwh/services/ovirt-engine-dwhd/ovirt-engine-dwhd.py: Permission denied -- Subject: Process /usr/share/ovirt-engine-dwh/services/ovirt-engine-dwhd/ovirt-engine-dwhd.py could not be executed
Indeed, the referenced script was not marked executable. Fixing it manually and restarting the service showed that this would succeed. But there is one problem. This change is not persisted. On the next deployment run, the hosted-engine VM will be deleted and re-created again. When searching for a nicer solution I found that this bug is actually already fixed in the latest release of
ovirt-engine-dwh-4.4.0-1.el8.noarch.rpmbut the appliance image (ovirt-engine-appliance-4.4-20200212182535.1.el8.x86_64) was only includingovirt-engine-dwh-4.4.0-0.0.master.20200206083940.el7.noarchand there is no newer appliance image. That’s part of the experience when trying alpha releases but it’s not a blocker. Eventually I found that there is a directory where you can place an Ansible tasks file which will be executed in the hosted-engine VM before the setup is run. So I created the filehooks/enginevm_before_engine_setup/yum_update.ymlin the/usr/share/ansible/roles/ovirt.hosted_engine_setup/directory with the following content:--- - name: Update all packages package: name: '*' state: latest
From then on each deployment attempt was first updating the packages including ‘ovirt-engine-dwh’ in the VM before the
hosted-enginewould continue to configure and restart the service. - The next issue was suddenly appearing when I tried to re-run the deployment. The Ansible code would fail early with an error that it cannot update the routing rules on the hypervisor:
2020-02-18 16:17:38,330+0100 DEBUG ansible on_any args
kwargs 2020-02-18 16:17:38,664+0100 INFO ansible task start {'status': 'OK', 'ansible_type': 'task', 'ansible_playbook': '/usr/share/ovirt-hosted-engine-setup/ansible/trigger_role.yml', 'ansible_task': 'ovirt.hosted_engine_setup : Add IPv4 outbo und route rules'} 2020-02-18 16:17:38,664+0100 DEBUG ansible on_any args TASK: ovirt.hosted_engine_setup : Add IPv4 outbound route rules kwargs is_conditional:False 2020-02-18 16:17:38,665+0100 DEBUG ansible on_any args localhostTASK: ovirt.hosted_engine_setup : Add IPv4 outbound route rules kwargs 2020-02-18 16:17:39,214+0100 DEBUG var changed: host "localhost" var "result" type " " value: "{ "changed": true, "cmd": [ "ip", "rule", "add", "from", "192.168.222.1/24", "priority", "101", "table", "main" ], "delta": "0:00:00.002805", "end": "2020-02-18 16:17:38.875350", "failed": true, "msg": "non-zero return code", "rc": 2, "start": "2020-02-18 16:17:38.872545", "stderr": "RTNETLINK answers: File exists", "stderr_lines": [ "RTNETLINK answers: File exists" ], "stdout": "", "stdout_lines": [] }" So I was checking the rules manually and yes, they were already there. I thought that’s an easy case, that must be a simple idempotency issue in the Ansible code. But when looking up the code there was already a condition in place that should prevent this case from happening. Even after multiple attempts to debug this code, I couldn’t find the reason why this check is failing. Eventually I found the GitHub pull request #96 where someone was already refactoring this code with a commit message “Hardening existing ruleset lookup”. So I forward-ported the patch to the release 1.0.35 which fixed the problem. The PR is already open for more than a year with no indication that it would be merged soon, so I still reported the issue in ovirt-ansible-hosted-engine-setup #289.
I only found out aboutovirt-hosted-engine-cleanupa few hours later, so with its help you can easily work-around this issue by cleaning up the installation before another retry. - Another though to debug but easy to fix issue popped up after the hosted-engine VM setup completed and the Ansible role was checking the oVirt events for errors:
2020-02-19 01:46:53,723+0100 ERROR ansible failed { "ansible_host": "localhost", "ansible_playbook": "/usr/share/ovirt-hosted-engine-setup/ansible/trigger_role.yml", "ansible_result": { "_ansible_no_log": false, "changed": false, "msg": "The host has been set in non_operational status, deployment errors: code 4035: Gluster command [] failed on server ., code 10802: VDSM loki.oasis.home command GlusterServersListVDS failed: The method does not exist or is not available: {'method': 'GlusterHost.list'}, fix accordingly and re-deploy." }, "ansible_task": "Fail with error description", "ansible_type": "task", "status": "FAILED", "task_duration": 0 } This error is not in the Ansible code anymore but the engine itself fails to query the GlusterFS status on the hypervisor. This is done via VDSM, a daemon that runs on each oVirt hypervisor and manages the hypervisor configuration and status. Maybe the VDSM log (
/var/log/vdsm/vdsm.log) reveals more insights:2020-02-19 01:46:45,786+0100 INFO (jsonrpc/7) [jsonrpc.JsonRpcServer] RPC call Host.getCapabilities succeeded in 3.33 seconds (__init__:312) 2020-02-19 01:46:45,981+0100 INFO (jsonrpc/1) [jsonrpc.JsonRpcServer] RPC call GlusterHost.list failed (error -32601) in 0.00 seconds (__init__:312)
Seems that regular RPC calls to VDSM are successful but only the GlusterFS query is failing. I tracked down the source code of this implementation and found that there is a CLI command that can be used to run this query:
# vdsm-client --gluster-enabled -h Traceback (most recent call last): File "/usr/lib/python3.6/site-packages/vdsmclient/client.py", line 276, in find_schema with_gluster=gluster_enabled) File "/usr/lib/python3.6/site-packages/vdsm/api/vdsmapi.py", line 156, in vdsm_api return Schema(schema_types, strict_mode, *args, **kwargs) File "/usr/lib/python3.6/site-packages/vdsm/api/vdsmapi.py", line 142, in __init__ with io.open(schema_type.path(), 'rb') as f: File "/usr/lib/python3.6/site-packages/vdsm/api/vdsmapi.py", line 95, in path ", ".join(potential_paths)) vdsm.api.vdsmapi.SchemaNotFound: Unable to find API schema file, tried: /usr/lib/python3.6/site-packages/vdsm/api/vdsm-api-gluster.pickle, /usr/lib/python3.6/site-packages/vdsm/api/../rpc/vdsm-api-gluster.pickleAh, that’s better. I love such error messages. Thanks to that it was not so hard to find, that I actually overlooked to install the
vdsm-glusterpackage on the hypervisor.
That’s it after that the deployment completed successfully:
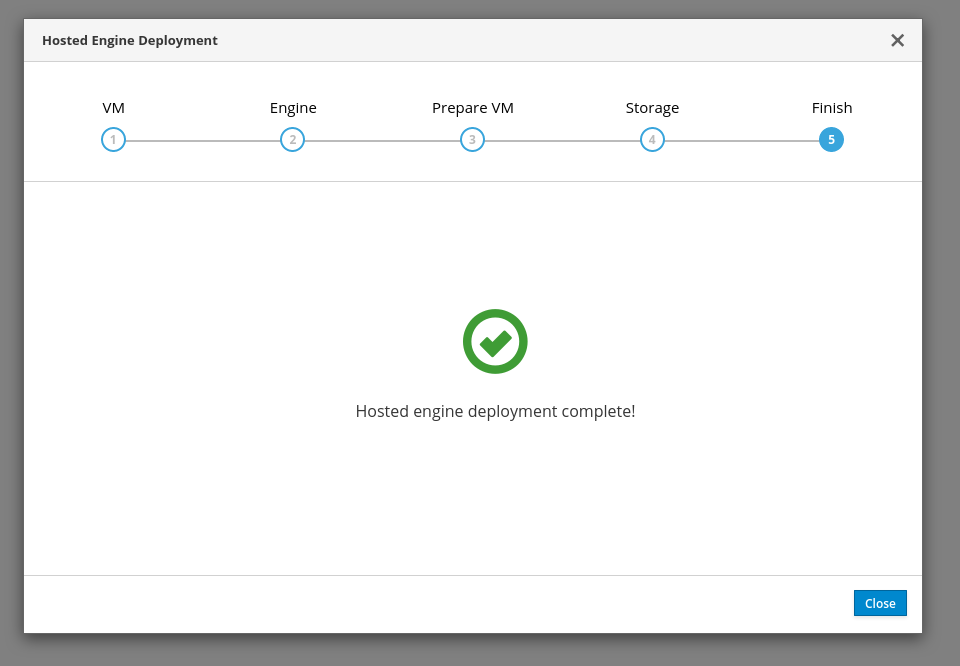
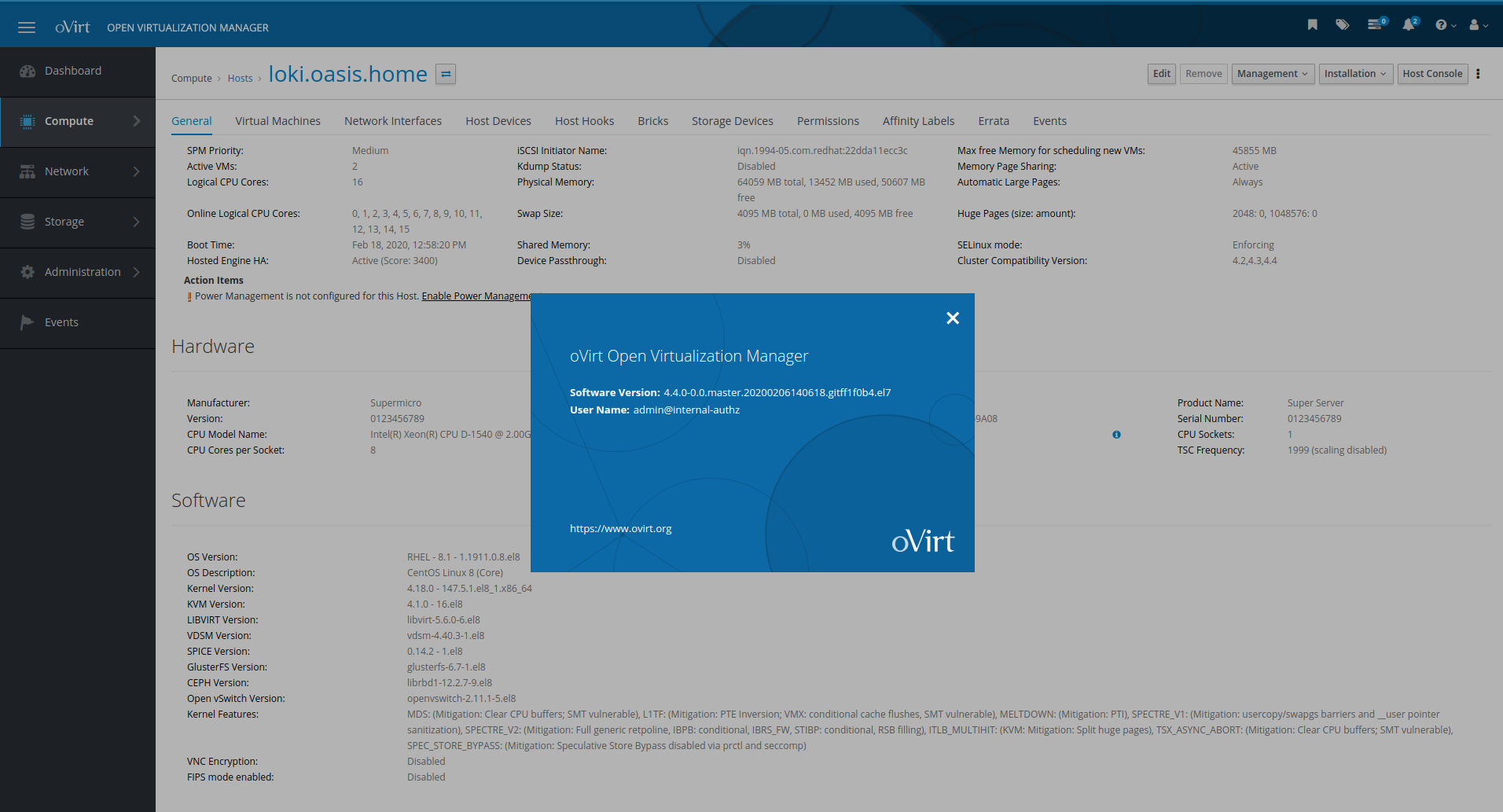
And finally a screenshot of the oVirt 4.4-alpha administration console. Yes, it works:
Conclusion
At the end the of the day most of the issues happened because I was not very familiar with the setup procedure and at the same time refused to follow any setup instructions for an older release. There were a minor bug with the ovirt-engine-dwh restart issue, that was already fixed upstream but didn’t made it yet into the hosted-engine appliance image. Something that is expected in an alpha release.
I also quickly setup some VMs to test the basic functionality of oVirt and couldn’t find any major issues so far. I guess most people using oVirt are much more experienced with it than me anyway, so there shouldn’t be any concerns in trying oVirt 4.4-alpha yourself. To me that was an interesting experience and I’m very happy about the Ansible integration that this project is pushing. It was also a nice experience to use Cockpit and I believe that’s definitely something that makes this product more appealing to setup and use for a wide range of IT professionals. As long as it can be done via command line too, I’ll be happy.